인공지능
Artificial intelligence
인공지능(AI)은 인간을 포함한 동물이 보여주는 자연 지능과는 달리 기계에 의해 증명되는 지능이다.AI 연구는 지능형 에이전트의 연구 분야로, 환경을 인지하고 목표 [a]달성 가능성을 극대화하는 모든 시스템을 말한다.
"인공지능"이라는 용어는 이전에 "학습"과 "문제 해결"과 같이 인간의 마음과 관련된 "인간" 인지 기술을 모방하고 보여주는 기계를 설명하기 위해 사용되었습니다.이 정의는 이제 AI를 합리성과 행동 면에서 설명하는 주요 AI 연구자들에 의해 거부되어 왔고, 이는 지능을 [b]표현하는 방법에 제한을 두지 않는다.
AI 애플리케이션에는 고급 웹 검색 엔진(예: Google), 추천 시스템(YouTube, Amazon 및 Netflix에서 사용), 인간의 음성 이해(예: Siri 및 Alexa), 자가 운전 자동차(예: Tesla), 자동 의사결정 및 전략 게임 시스템(예: 체스 및 Go)[2]의 최고 수준 경쟁이 포함됩니다.기계가 점점 더 능력을 갖추게 됨에 따라, "지능"을 필요로 하는 것으로 간주되는 태스크는 종종 AI [3]효과로 알려진 현상인 AI의 정의에서 제거된다.예를 들어 광학식 문자 인식은 [4]AI로 간주되는 것에서 제외되는 경우가 많아 일상적인 [5]기술이 되었다.
인공지능은 1956년에 학술 분야로 설립되었고, 그 이후 수년간 여러 차례의 [6][7]낙관론이 일었고, 실망과 자금의 손실("AI 겨울"[8][9]로 알려져 있음), 새로운 접근법, 성공, 그리고 새로운 [7][10]자금 지원이 뒤따랐다.AI 연구는 설립 이래 두뇌 시뮬레이션, 인간 문제 해결 모델링, 형식 논리, 지식의 대규모 데이터베이스, 동물 행동을 모방하는 것을 포함한 많은 다른 접근 방식을 시도하고 폐기해 왔다.21세기 초 수십 년 동안, 고도로 수학 통계적인 기계 학습이 분야를 지배해 왔고, 이 기술은 산업과 [10][11]학계에서 많은 도전적인 문제들을 해결하는 데 도움을 주면서 매우 성공적이었습니다.
AI 연구의 다양한 하위 분야는 특정 목표와 특정 도구의 사용을 중심으로 합니다.인공지능 연구의 전통적인 목표는 추론, 지식 표현, 계획, 학습, 자연어 처리, 지각, 그리고 [c]물체를 움직이고 조작하는 능력을 포함한다.일반 지능(독단적인 문제를 해결하는 능력)은 이 분야의 장기적인 [12]목표 중 하나이다.이러한 문제를 해결하기 위해 AI 연구진은 검색 및 수학적 최적화, 형식 논리, 인공 신경망, 통계, 확률 및 경제성에 기반한 방법 등 광범위한 문제 해결 기술을 채택하고 통합했습니다.AI는 또한 컴퓨터 과학, 심리학, 언어학, 철학, 그리고 많은 다른 분야들을 이용한다.
이 분야는 "인간의 지능을 매우 정확하게 기술할 수 있어 기계가 그것을 시뮬레이션하도록 만들 수 있다"[d]는 가정에 기초했다.이것은 인간과 같은 지능을 가진 인공적인 존재를 창조하는 마음과 윤리적 결과에 대한 철학적 논쟁을 불러일으켰다; 이러한 문제들은 [14]고대부터 신화, 소설, 철학에 의해 탐구되어 왔다.컴퓨터 과학자들과 철학자들은 인공지능의 합리적인 능력이 유익한 [e]목표를 향해 나아가지 않는다면 인류에게 실존적 위험이 될 수도 있다고 제안했다.
역사
소설과 초기 개념

지능을 가진 인공적인 존재는 고대에 [15]스토리텔링 장치로 등장했고 메리 셸리의 프랑켄슈타인이나 카렐 차펙의 R.U.R.[16]에서와 같이 소설에서 흔히 볼 수 있었다. 이 캐릭터들과 그들의 운명은 현재 인공지능의 [17]윤리학에서 논의되고 있는 것과 같은 문제들을 많이 제기하였다.
기계적이거나 "형식적인" 추론의 연구는 고대 철학자들과 수학자들로부터 시작되었다.수학 논리의 연구는 앨런 튜링의 계산 이론으로 이어졌고, 그것은 기계가 "0"과 "1"처럼 간단한 기호를 섞음으로써 상상할 수 있는 어떤 수학적 추론 행위도 시뮬레이션할 수 있다고 제안했다.디지털 컴퓨터가 어떠한 공식 추론 과정도 시뮬레이션할 수 있다는 이러한 통찰력을 처치-튜링 [18]논문이라고 합니다.
처치-튜링 논문은 신경생물학, 정보 이론, 사이버네틱스의 동시 발견과 함께 연구자들이 전자 [19]두뇌의 구축 가능성을 고려하도록 이끌었다.현재 일반적으로 AI로 인식되고 있는 최초의 작품은 1943년 튜링 완전 "인공 뉴런"[20]에 대한 맥컬러치와 피츠의 정식 디자인이었다.
초기 연구
1950년대에 이르러 기계 지능을 달성하는 방법에 대한 두 가지 비전이 나타났다.심볼릭 AI 또는 GOFAI로 알려진 한 가지 비전은 컴퓨터를 사용하여 세계를 상징적으로 표현하고 세계를 추론할 수 있는 시스템을 만드는 것이었다.지지자 중에는 앨런 뉴웰, 허버트 A가 있었다. 사이먼, 그리고 마빈 민스키.이 접근방식과 밀접하게 관련되어 있는 것은 "휴리스틱 서치" 접근방식입니다.이 접근방식은 지성을 해답의 가능성을 탐색하는 문제에 비유합니다.연결주의 접근법으로 알려진 두 번째 비전은 학습을 통해 지능을 달성하고자 했다.이 접근법의 지지자인 프랭크 로젠블랫은 [21]뉴런의 연결에서 영감을 얻은 방식으로 퍼셉트론을 연결하려고 했습니다.James Manyika와 다른 사람들은 정신에 대한 두 가지 접근법 (상징적 AI)과 뇌 (연결주의자)를 비교했다.Manyika는 상징적 접근법이 데카르트, 불, 고틀롭 프레지, 버트런드 러셀 등의 지적 전통과의 연관성 때문에 이 시기에 인공지능의 추진력을 지배했다고 주장한다.사이버네틱스나 인공 신경망에 기반한 연결주의 접근법은 배경에 밀려났지만 최근 수십 [22]년 동안 새로운 주목을 받고 있다.
AI 연구 분야는 1956년 [f][25]다트머스 대학의 워크숍에서 탄생했다.참석자들은 AI [g]연구의 창시자이자 리더가 되었다.그들과 그들의 학생들은 언론이 "놀라움"[h]이라고 묘사하는 프로그램을 제작했다: 컴퓨터는 체커 전략을 배우고, 대수학에서 단어 문제를 풀고, 논리 정리를 증명하고,[i][27] 영어를 말하는 것이었다.1960년대 중반까지, 미국에서의 연구는 국방부에[28] 의해 많은 자금을 지원받았고, 연구소는 [29]전 세계에 설립되었다.
1960년대와 1970년대의 연구원들은 상징적 접근법이 결국 인공지능을 가진 기계를 만드는 데 성공할 것이라고 확신했고 이것을 그들 [30]분야의 목표로 여겼다.허버트 사이먼은 "20년 안에 기계가 사람이 할 수 있는 모든 일을 할 수 있게 될 것"이라고 예측했다.[31]마빈 민스키는 "한 세대 안에...'지능형 정보'를 만드는 문제는 실질적으로 해결될 것이다."[32]
그들은 남은 과제 중 일부의 어려움을 인식하지 못했다.1974년 제임스 라이트힐[33] 경의 비판과 보다 생산적인 프로젝트에 자금을 지원하라는 미 의회의 지속적인 압력에 따라 미국과 영국 정부는 AI에 대한 탐사 연구를 중단했다.그 후 몇 년은 AI 프로젝트에 대한 자금 [8]조달이 어려운 시기인 "AI 겨울"로 불리게 되었다.
전문가 시스템에서 기계 학습까지
1980년대 초, 인공지능 연구는 인간 전문가들의 지식과 분석 능력을 시뮬레이션한 AI 프로그램의 한 형태인 전문가 [34]시스템의 상업적 성공으로 되살아났다.1985년까지 AI 시장은 10억 달러 이상에 달했다.동시에, 일본의 5세대 컴퓨터 프로젝트는 미국과 영국 정부들로 하여금 학술 [7]연구를 위한 자금을 회복하도록 자극했다.그러나 1987년 리스프머신 시장의 붕괴를 시작으로 AI는 다시 한 번 평판을 잃었고, 두 번째 더 긴 겨울이 시작되었다.[9]
많은 연구자들은 상징적인 접근법이 인간의 인지, 특히 지각, 로봇 공학, 학습과 패턴 인식의 모든 과정을 모방할 수 있을지 의심하기 시작했다.많은 연구자들이 특정 AI [35]문제에 대한 "상징 이하" 접근법을 조사하기 시작했다.로드니 브룩스 같은 로봇 연구가들은 상징적인 AI를 거부하고 로봇이 움직이고, 살아남고,[j] 환경을 학습할 수 있도록 하는 기본적인 공학 문제에 초점을 맞췄다.신경 [40]네트워크와 "연결주의"에 대한 관심은 1980년대 중반 제프리 힌튼, 데이비드 루멜하트 등에 의해 되살아났다.뉴럴 네트워크, 퍼지 시스템, 그레이 시스템 이론, 진화 계산 및 통계 또는 수학적 최적화에서 도출된 많은 도구와 같은 소프트 컴퓨팅 도구가 80년대에 개발되었습니다.
AI는 1990년대 후반과 21세기 초에 구체적인 문제에 대한 해결책을 찾아냄으로써 점차 명성을 회복했다.좁은 초점은 연구자들이 검증 가능한 결과를 만들고, 더 많은 수학적 방법을 활용하고, 다른 분야(통계학, 경제학, 수학 [41]등)와 협력할 수 있게 했다.1990년대에는 거의 "인공지능"[11]으로 묘사되지 않았지만, 2000년에는 AI 연구자들이 개발한 솔루션이 널리 사용되었다.
컴퓨터의 고속화, 알고리즘의 향상, 대량의 데이터에의 액세스에 의해, 머신 러닝과 지각의 진보를 실현했습니다.[42]데이터를 많이 사용하는 딥 러닝 방법은 2012년경부터 정확도 벤치마크를 지배하기 시작했습니다.블룸버그의 잭 클라크에 따르면 2015년은 구글 내에서 AI를 사용하는 소프트웨어 프로젝트가 2012년 '스포라딕 사용'에서 2700여 [k]개의 프로젝트로 증가하는 등 인공지능에 획기적인 해였다.그는 클라우드 컴퓨팅 인프라의 증가와 연구 툴 및 [10]데이터셋의 증가로 인해 저렴한 뉴럴 네트워크가 증가했기 때문이라고 말합니다.2017년 조사에서 5개 기업 중 1개 기업이 "일부 제품 또는 프로세스에 [43]AI를 통합"했다고 보고했습니다.AI에 [44]대한 연구량(총 출판물로 측정)은 2015-2019년에 50% 증가했다.
많은 학계 연구자들이 인공지능이 더 이상 다재다능하고 완전히 지능적인 기계를 만든다는 본래의 목표를 추구하지 않는다고 우려했다.현재 연구의 대부분은 통계 AI를 포함하고 있는데, 통계 AI는 특정 문제를 해결하는 데 압도적으로 사용되며, 심지어 딥 러닝과 같은 매우 성공적인 기술도 포함하고 있다.이러한 우려로 인해 2010년대까지 [12]여러 개의 자금이 풍부한 기관이 있던 인공지능(또는 "AGI")의 하위 분야가 생겨났다.
목표들
지능을 시뮬레이션(또는 생성하는)하는 일반적인 문제는 하위 문제로 세분화되었습니다.이것들은 연구자들이 지능형 시스템이 보여줄 것으로 기대하는 특정한 특성이나 능력으로 구성되어 있습니다.아래에 설명된 특성이 가장 [c]주목을 받고 있습니다.
추론, 문제 해결
초기 연구자들은 인간이 퍼즐을 풀거나 논리적 [45]추론을 할 때 사용하는 단계별 추론을 모방한 알고리즘을 개발했다.1980년대 후반과 1990년대까지 AI 연구는 불확실하거나 불완전한 정보를 다루는 방법을 개발했으며 확률과 [46]경제성의 개념을 채택했다.
이들 알고리즘의 대부분은 문제가 [47]커질수록 기하급수적으로 느려지는 "공역 폭발"을 경험했기 때문에 큰 추론 문제를 해결하기에는 불충분하다는 것이 입증되었다.인간조차도 초기 AI 연구가 모델링할 수 있었던 단계별 추론을 거의 사용하지 않는다.그들은 빠르고 직관적인 [48]판단을 통해 대부분의 문제를 해결합니다.
지식 표현

지식 표현과 지식[49] 공학을 통해 AI 프로그램은 질문에 지능적으로 대답하고 실제 사실에 대해 추론할 수 있습니다.
"존재하는 것"의 표현은 온톨로지입니다.소프트웨어 에이전트가 그것들을 [50]해석할 수 있도록 공식적으로 기술된 객체, 관계, 개념 및 속성 집합입니다.가장 일반적인 온톨로지는 상위 온톨로지라고 불리며, 특정 지식 도메인(관심 분야 또는 관심 영역)에 대한 특정 지식을 다루는 도메인 온톨로지 간의 중재자 역할을 합니다.진정한 지능형 프로그램은 또한 상식적인 지식, 즉 일반인이 알고 있는 사실들에 접근할 필요가 있다.온톨로지의 의미론은 일반적으로 Web Ontology [51]Language와 같은 설명 로직으로 표현됩니다.
AI조사 도구 개체, 속성 범주와 물체 사이의 관계 등과 같은 특정 도메인;[51]상황, 사건, 주, 그리고 시간을 나타내는 데,[52]과 효과를 유발했는지;지식에 대해[53]지식(우리는 다른 사람들이 알고 있는 내용을 알고 있는 것);개발했다.까지 그들은 다르게 a 들었다 인간은 사실이 생각하[54]기본 추리(것들nd는 다른 사실이 변경되어도 true로 유지됩니다).또, 다른 도메인도 마찬가지입니다.AI의 가장 어려운 문제들 중 하나는 상식적인 지식의 폭(일반인이 알고 있는 원자적인 사실의 수는 어마어마하다),[56] 그리고 대부분의 상식적인 지식의 준상징적 형태(사람들이 알고 있는 것의 대부분은 [48]말로 표현할 수 있는 사실이나 진술로 표현되지 않는다)이다.
공식적인 지식 표현은 콘텐츠 기반 인덱싱 및 검색,[57] 장면 해석,[58] 임상 의사 결정 지원,[59] 지식 발견(대형 데이터베이스에서 [60]"흥미롭고 실행 가능한" 추론) 및 기타 [61]분야에서 사용됩니다.
계획.
계획을 세울 수 있는 인텔리전트 에이전트는 세계 상태를 나타내며, 그들의 행동이 세계 상태를 어떻게 변화시킬지 예측하고,[62] 이용 가능한 선택의 효용(또는 "가치")을 극대화하는 선택을 합니다.기존의 계획 문제에서 에이전트는 그것이 세계에서 유일하게 동작하는 시스템이라고 가정할 수 있으며,[63] 이를 통해 에이전트는 그 동작의 결과를 확신할 수 있습니다.단, 에이전트가 유일한 행위자가 아닌 경우에는 불확실한 상황에서 에이전트가 이유를 제시하고 지속적으로 환경을 재평가하여 [64]적응할 것을 요구합니다.멀티에이전트 플래닝은 다수의 에이전트의 협력과 경쟁을 사용하여 특정 목표를 달성합니다.이와 같은 새로운 행동은 진화 알고리즘과 군집 [65]지능에 의해 사용된다.
학습
AI 연구의 [l]기본 개념인 머신러닝(ML)은 경험을 [m]통해 자동으로 개선되는 컴퓨터 알고리즘을 연구하는 학문이다.
비지도 학습은 입력 흐름에서 패턴을 찾습니다.지도 학습은 인간이 먼저 입력 데이터에 라벨을 붙여야 하며, 분류와 수치 회귀라는 두 가지 주요 변종이 있다.분류는 어떤 범주에 속하는지 결정하기 위해 사용됩니다. 이 프로그램은 여러 범주의 여러 가지 예를 보고 새로운 입력을 분류하는 방법을 학습합니다.회귀는 입력과 출력 사이의 관계를 설명하고 입력이 변화함에 따라 출력이 어떻게 변화해야 하는지를 예측하는 함수를 생성하려는 시도입니다.분류자와 회귀 학습자 모두 알 수 없는(아마도 암묵적인) 함수를 학습하려는 "함수 근사자"로 볼 수 있습니다. 예를 들어 스팸 분류자는 전자 메일의 텍스트에서 "스팸" 또는 "[69]스팸 아님"의 두 범주 중 하나에 매핑되는 함수를 학습하는 것으로 볼 수 있습니다.강화 학습에서는 에이전트가 좋은 응답에 대해 보상을 받고 나쁜 응답에 대해 벌을 받습니다.에이전트는 응답을 분류하여 문제 공간에서 [70]작동하기 위한 전략을 수립합니다.이전학습은 한 문제에서 얻은 지식을 새로운 [71]문제에 적용하는 것이다.
계산 학습 이론은 계산 복잡도, 표본 복잡도(필요한 데이터의 양)[72] 또는 최적화의 다른 개념으로 학습자를 평가할 수 있습니다.
자연어 처리
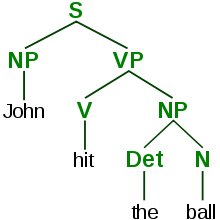
자연어 처리(NLP)[73]를 통해 기계는 인간의 언어를 읽고 이해할 수 있습니다.충분히 강력한 자연어 처리 시스템은 자연어 사용자 인터페이스를 가능하게 하고 뉴스 와이어 텍스트와 같은 인간이 작성한 소스로부터 직접 지식을 습득할 수 있게 할 것이다.NLP의 간단한 응용 프로그램에는 정보 검색, 질문 응답 및 기계 [74]번역이 포함됩니다.
심볼릭 AI는 문장의 깊은 구조를 논리로 변환하기 위해 형식적인 구문을 사용했다.이것은 논리의[47] 난해성과 상식적인 [56]지식의 폭 때문에 유용한 응용 프로그램을 만들어내지 못했다.최신 통계 기법에는 동시 발생 빈도(한 단어가 다른 단어 근처에 나타나는 빈도), "키워드 스팟팅"(정보를 검색하기 위해 특정 단어를 검색), 변압기 기반 딥 러닝(텍스트에서 패턴을 찾는)"[75] 등이 포함됩니다.페이지 또는 단락 수준에서 허용 가능한 정확도를 달성했으며 2019년까지 일관성 있는 [76]텍스트를 생성할 수 있다.
인식

기계 인식은[77] 센서(카메라, 마이크, 무선 신호, 액티브 라이더, 소나, 레이더 및 촉각 센서 등)로부터의 입력을 사용하여 세계의 측면을 추론할 수 있는 능력입니다.응용 프로그램에는 음성 인식,[78] 얼굴 인식, 물체 [79]인식이 포함됩니다.컴퓨터 비전은 시각 [80]입력을 분석하는 능력이다.
움직임과 조작
인공지능은 로봇 [81]공학에서 많이 사용된다.현지화는 로봇이 자신의 위치를 알고 환경을 지도화하는 방법입니다.작고 정적이며 가시적인 환경이 주어지면, 이것은 쉽다. 그러나 (내시경 검사에서) 환자의 호흡 신체 내부와 같은 동적 환경은 더 [82]큰 어려움을 야기한다.
모션 플래닝은 움직임 작업을 개별 관절 움직임과 같은 "원본"으로 분해하는 과정입니다.이러한 움직임에는 종종 순응적인 움직임, 즉 움직임이 물체와 물리적 접촉을 유지해야 하는 과정이 수반됩니다.로봇은 마찰과 기어 [83]미끄러짐에도 불구하고 효율적으로 움직이는 방법을 경험을 통해 배울 수 있습니다.
소셜 인텔리전스

감성 컴퓨팅은 인간의 감정, 감정 및 [85]기분을 인식, 해석, 처리 또는 시뮬레이션하는 시스템으로 구성된 학문 간 통합입니다.예를 들어, 일부 가상 어시스턴트는 대화나 유머러스한 농담을 하도록 프로그램되어 있습니다.이것에 의해, 인간과의 상호작용의 감정적인 역학에 보다 민감하게 반응하거나 인간-컴퓨터와의 상호작용을 용이하게 할 수 있습니다.그러나 이는 순진한 사용자에게 [86]기존 컴퓨터 에이전트가 실제로 얼마나 지능적인지에 대한 비현실적인 개념을 심어주는 경향이 있습니다.감성 컴퓨팅과 관련된 중간 정도의 성공에는 텍스트 감정 분석과 더 최근에는 멀티모달 감정 분석)이 포함됩니다. 여기서 AI는 비디오로 촬영된 [87]피험자가 보여주는 영향을 분류합니다.
일반 인텔리전스
일반적인 지능을 가진 기계는 인간의 지능과 유사한 폭과 다용도로 다양한 문제를 해결할 수 있습니다.인공지능을 개발하는 방법에 대한 몇 가지 경쟁적인 생각들이 있다.Hans Moravec과 Marvin Minsky는 서로 다른 개별 도메인에서의 작업이 일반 [88]지능을 가진 고급 다중 에이전트 시스템 또는 인지 아키텍처에 통합될 수 있다고 주장합니다.페드로 도밍고스는 AGI로 이어질 수 있는 개념적으로 간단하지만 수학적으로 어려운 "마스터 알고리즘"[89]이 있기를 희망합니다.다른[90] 사람들은 인공 두뇌나 모의 아동[n] 발달과 같은 의인화된 특징이 언젠가 일반 지능이 나타나는 임계점에 도달할 것이라고 믿는다.
도구들
검색 및 최적화
AI의 많은 문제는 많은 가능한 [91]해결책을 지능적으로 검색함으로써 이론적으로 해결할 수 있습니다.추론은 검색을 수행하는 것으로 요약할 수 있습니다.예를 들어 논리적 증거는 전제에서 결론으로 이어지는 경로를 찾는 것으로 볼 수 있다. 여기서 각 단계는 추론 [92]규칙의 적용이다.계획 알고리즘은 목표와 하위 목표의 트리를 검색하여 목표의 경로를 찾습니다. 이 프로세스는 평균-끝 [93]분석이라고 합니다.사지를 움직이고 물체를 잡기 위한 로봇 알고리즘은 구성 공간에서 [94]로컬 검색을 사용합니다.
단순한[95] 철저한 검색으로는 대부분의 실제 문제에 충분하지 않습니다. 검색 공간(검색할 장소의 수)은 천문학적인 숫자로 빠르게 증가합니다.그 결과 검색이 너무 느리거나 완료되지 않습니다.많은 문제에 대한 해결책은 목표에 도달할 가능성이 더 높은 사람을 우선시하고 더 짧은 단계에서 그렇게 하는 선택에 우선순위를 두는 "휴리스틱스" 또는 "경험 규칙"을 사용하는 것이다.일부 검색 방법론에서 휴리스틱스는 목표('검색 트리 가지치기'라고 함)로 이어질 가능성이 낮은 일부 선택지를 제거하는 역할을 할 수도 있습니다.휴리스틱스는 솔루션이 존재하는 경로에 [96]대한 "최상의 추측"을 프로그램에 제공합니다.휴리스틱스는 솔루션 검색을 더 작은 표본 [97]크기로 제한합니다.

최적화의 수학적 이론에 기초한 매우 다른 종류의 연구가 1990년대에 두드러졌다.많은 문제에 대해 추측의 형태로 검색을 시작한 후 더 이상 수정할 수 없을 때까지 점진적으로 추측을 수정할 수 있습니다.이러한 알고리즘은 블라인드 힐 클라이밍이라고 할 수 있습니다.경관상의 임의의 지점에서 검색을 시작하고 나서 점프를 하거나 스텝을 밟아 정상에 도달할 때까지 추측을 계속합니다.다른 관련 최적화 알고리즘에는 랜덤 최적화, 빔 검색 및 시뮬레이션 어닐링과 [98]같은 메타 휴리스틱이 포함됩니다.진화적 계산은 최적화 검색의 형태를 사용합니다.예를 들어, 그들은 유기체의 집단(추측)에서 시작해서 각 세대에서 살아남기 위해 가장 적합한 것만을 선택하면서 돌연변이와 재조합을 할 수 있다.고전적인 진화 알고리즘은 유전자 알고리즘, 유전자 발현 프로그래밍,[99] 유전자 프로그래밍을 포함한다.또는 분산 검색 프로세스는 군집 지능 알고리즘을 통해 조정할 수 있습니다.검색에 사용되는 두 가지 인기 있는 군집 알고리즘은 입자 군집 최적화(새떼에서 영감을 받은)와 개미 군집 최적화(개미 [100]흔적에서 영감을 받은)입니다.
논리
논리는[101] 지식 표현과 문제 해결에 사용되지만 다른 문제에도 적용될 수 있습니다.예를 들어, 위성 계획 알고리즘은 계획을 위해[102] 논리를 사용하고 귀납 논리 프로그래밍은 [103]학습을 위한 방법이다.
AI 연구에는 몇 가지 다른 형태의 논리가 사용된다.명제논리는[104] "또는"과 "아니오"와 같은 진실함수를 포함한다.1차[105] 논리는 수량화 및 술어를 추가하여 객체, 속성 및 서로 간의 관계에 대한 사실을 표현할 수 있습니다.퍼지 논리는 "앨리스는 늙었다" (또는 부자이거나 키가 크거나 배고프다)와 같은 언어학적으로 너무 부정확한 진술에 "진실의 정도"(0과 1)를 할당합니다.[106]디폴트 로직, 비단조 로직 및 제한은 디폴트 추론 및 자격 [55]문제에 도움이 되도록 설계된 로직 형식입니다.설명 논리학,[51] 상황 미적분, 사건 미적분, 그리고 유창한 미적분(사건과 [52]시간을 나타냄), 인과적분,[53] 믿음 미적분(신앙 수정), 그리고 모달 [54]논리학과 같은 특정한 영역의 지식을 다루기 위해 논리학의 확장이 고안되었습니다.멀티 에이전트 시스템에서 발생하는 모순되거나 모순되지 않는 문장을 모델링하는 논리(예: 패러콘존재 논리)[citation needed]도 설계되어 있습니다.
불확실한 추론을 위한 확률론적 방법

AI의 많은 문제(추론, 계획, 학습, 지각, 로봇 공학 등)는 에이전트가 불완전하거나 불확실한 정보를 조작해야 한다.AI 연구진은 확률론과 [107]경제학의 방법을 이용해 이러한 문제들을 해결할 수 있는 여러 가지 도구를 고안해냈다.베이지안[108] 네트워크는 추론(베이지안 추론 [o][110]알고리즘 사용), 학습(기대 최대화 [p][112]알고리즘 사용), 계획(의사결정 [113]네트워크 사용) 및 지각(동적인 베이지안 [114]네트워크 사용)을 포함한 다양한 문제에 사용할 수 있는 매우 일반적인 도구입니다.확률론적 알고리즘은 데이터 스트림에 대한 필터링, 예측, 스무딩 및 설명 찾기에 사용될 수 있으며, 지각 시스템이 시간에 따라 발생하는 프로세스(예: 숨겨진 마르코프 모델 또는 칼만 필터)[114]를 분석하는 데 도움이 된다.
경제학에서 중요한 개념은 "유틸리티"입니다.유틸리티는 인텔리전트 에이전트에 대한 가치의 척도입니다.결정 이론, 결정 [115]분석 및 정보 가치 [116]이론을 사용하여 에이전트가 어떻게 선택과 계획을 할 수 있는지를 분석하는 정확한 수학 도구가 개발되었습니다.이러한 툴에는 마르코프 의사결정 프로세스,[117] 동적 의사결정 네트워크,[114] 게임 이론 및 메커니즘 [118]설계와 같은 모델이 포함됩니다.
분류자 및 통계학습방법
가장 간단한 AI 애플리케이션은 분류기("반짝이면 다이아몬드")와 컨트롤러("다이아몬드이면 픽업")의 두 가지 유형으로 나눌 수 있습니다.그러나 컨트롤러는 행동을 추론하기 전에 조건을 분류하기 때문에 분류는 많은 AI 시스템의 중심 부분을 형성한다.분류자는 패턴 일치를 사용하여 가장 가까운 일치를 결정하는 함수입니다.예를 들어 튜닝이 가능하기 때문에 AI에서 사용하기에 매우 매력적입니다.이러한 예를 관측치 또는 패턴이라고 합니다.지도 학습에서 각 패턴은 미리 정의된 특정 클래스에 속합니다.클래스는 결정해야 하는 사항입니다.클래스 레이블과 결합된 모든 관측치를 데이터 집합이라고 합니다.새로운 관찰이 수신되면, 그 관찰은 이전의 [119]경험에 근거해 분류된다.
분류자는 다양한 방법으로 훈련될 수 있습니다. 통계 및 기계 학습 접근법이 많이 있습니다.Decision Tree는 가장 단순하고 널리 사용되는 심볼 머신 [120]러닝 알고리즘입니다.K-근접 이웃 알고리즘은 1990년대 [121]중반까지 가장 널리 사용된 아날로그 AI였다.서포트 벡터 머신(SVM)과 같은 커널 방식은 1990년대에 [122]k-가장 가까운 네이버를 대체했습니다.보도에 따르면 순진한 베이즈 분류기는 구글에서 "가장 널리 사용되는 학습자"[123]인데,[124] 그 일부는 그 확장성 때문이다.뉴럴 네트워크는 [125]분류에도 사용됩니다.
분류기 성능은 데이터 세트 크기, 클래스 간 샘플 분포, 차원 및 소음 수준과 같은 분류할 데이터의 특성에 따라 크게 달라집니다.모형 기반 분류기는 가정된 모형이 실제 데이터에 매우 적합한 경우 성능이 우수합니다.그렇지 않으면, 일치하는 모델이 없고 정확성(속도나 확장성보다는)이 유일한 관심사라면, 대부분의 실용적인 데이터 세트에서 "[126]naive bayes"와 같은 모델 기반 분류기보다 차별적 분류기(특히 SVM)가 더 정확한 경향이 있다는 것이 통념입니다.
인공신경망

뉴럴[125] 네트워크는 인간 뇌의 뉴런 구조에서 영감을 받았습니다.단순한 "뉴론" N은 다른 뉴런으로부터의 입력을 받아들이는데, 각각의 뉴런이 활성화(또는 "발화")될 때, 뉴런 N이 스스로 활성화되어야 하는지 여부에 대한 가중된 "투표"를 한다.학습에는 훈련 데이터에 기초하여 이러한 무게를 조절하는 알고리즘이 필요합니다. 하나의 간단한 알고리즘은 하나의 활성화가 다른 것의 활성화를 촉발할 때 연결된 두 개의 뉴런 사이의 무게를 증가시키는 것입니다.뉴런은 연속적인 활성화 스펙트럼을 가지고 있다; 게다가, 뉴런은 직접 투표의 무게를 재는 대신 비선형 방식으로 입력을 처리할 수 있다.
현대 신경망은 입력과 출력 사이의 복잡한 관계를 모델링하고 데이터에서 패턴을 찾습니다.연속 기능 및 디지털 논리 연산까지 학습할 수 있습니다.뉴럴 네트워크는 수학적 최적화의 한 종류로 볼 수 있습니다.뉴럴 네트워크는 네트워크를 훈련함으로써 생성된 다차원 토폴로지에 대해 경사 강하를 수행합니다.가장 일반적인 훈련 기법은 역전파 [127]알고리즘입니다.뉴럴 네트워크의 다른 학습 기법으로는 헤비어 학습("함께 불타고, 함께 배선하고", GMDH 또는 경쟁 [128]학습이 있습니다.
네트워크의 주요 카테고리는 비순환형 또는 피드포워드형 뉴럴 네트워크(신호가 한 방향으로만 통과하는 경우)와 반복형 뉴럴 네트워크(이전 입력 이벤트의 피드백 및 단기 기억을 가능하게 하는 경우)입니다.가장 인기 있는 피드포워드 네트워크에는 퍼셉트론,[129] 다층 퍼셉트론 및 레이디얼 베이스 네트워크가 있습니다.
딥 러닝

딥[131] 러닝은 네트워크의 입력과 출력 사이에 여러 층의 뉴런을 사용한다.여러 레이어가 원시 입력에서 상위 수준의 피쳐를 점진적으로 추출할 수 있습니다.예를 들어 이미지 처리에서 하위 레이어는 가장자리를 식별하는 반면 상위 레이어는 숫자, 문자 또는 [132]얼굴과 같은 인간과 관련된 개념을 식별할 수 있다.딥 러닝은 컴퓨터 비전, 음성 인식, 이미지 분류[133] 등을 포함한 인공지능의 많은 중요한 하위 분야에서 프로그램의 성능을 획기적으로 향상시켰다.
딥 러닝은 종종 그것의 많은 또는 모든 계층에 대해 컨볼루션 신경망을 사용한다.컨볼루션 층에서, 각 뉴런은 뉴런의 수용장이라고 불리는 이전 층의 제한된 영역으로부터만 입력을 받습니다.이것은 [134]뉴런들 사이의 가중된 연결의 수를 상당히 줄일 수 있고,[135] 동물의 시각 피질의 조직과 유사한 계층을 만들 수 있습니다.
반복 신경 네트워크에서는 신호가 레이어를 통해 [136]두 번 이상 전파됩니다. 따라서 RNN은 딥 [137]러닝의 한 예입니다.RNN은 구배 [138]강하로 훈련될 수 있지만, 역 전파되는 장기 구배는 소멸 구배 [139]문제로 알려진 "소멸" 또는 "폭발"할 수 있다(즉, RNN은 소멸 구배 문제로 알려져 있다.대부분의 경우 [140]Long Short Term Memory(LSTM; 장기단기메모리) 기술을 통해 이를 방지할 수 있습니다.
전문 언어 및 하드웨어
리스프, 프롤로그, 텐서플로우 등 인공지능을 위한 전문 언어가 개발됐다.AI용으로 개발된 하드웨어는 AI 가속기와 뉴로모픽 컴퓨팅을 포함한다.
적용들
작업 필드

AI는 모든 지적 [141]작업과 관련이 있다.현대의 인공지능 기술은 널리 보급되어 있으며 여기에 [142]열거하기에는 너무 많다.기술이 주류에 도달하면 인공지능으로 간주되지 않는 경우가 많습니다. 이 현상을 AI [143]효과라고 합니다.
2010년대에 AI 애플리케이션은 가장 상업적으로 성공한 컴퓨팅 분야의 중심이었고, 일상생활의 유비쿼터스 기능이 되었습니다.인공 지능 검색 엔진에(구글 검색 같은), 온라인 advertisements,[144][non-primary 공급원이 필요하]추천 시스템(넷플릭스, 유투브 또는 아마존에 의해 제공)을 타깃으로 하는 인터넷 traffic,[145][146]광고(애드 센스, 페이스북), 무인 정찰기는 포함한 가상 단말기( 같은 시리 또는 알렉사)[147]무인 차량(대상 운전하는 사용된다.D스스로 운전하는 자동차), 자동 언어 트랜스.lation(Microsoft Translator, Google Translate), 얼굴 인식(Apple의 Face ID 또는 Microsoft의 DeepFace), 이미지 라벨링(Facebook, Apple의 iPhoto 및 TikTok에서 사용) 및 스팸 필터링.
특정 산업이나 기관의 문제를 해결하기 위해 사용되는 수천 개의 성공적인 AI 애플리케이션도 있습니다.예를 들어 에너지 저장,[148] 딥페이크,[149] 의료진단, 군사물류, 공급망 관리 등이 있습니다.
게임 플레이는 1950년대부터 인공지능의 힘을 시험해 왔다.딥 블루는 1997년 [150]5월 11일 세계 체스 챔피언 개리 카스파로프를 이긴 최초의 컴퓨터 체스 시스템이 되었다.2011년, Jeopardy! 퀴즈쇼 시범 경기에서 IBM의 질문 응답 시스템인 Watson은 Jeopardy! 챔피언인 Brad Rutter와 Ken Jennings를 큰 [151]차이로 물리쳤습니다.2016년 3월 알파고는 바둑 챔피언 이세돌과의 대결에서 5전 4승을 거두며 컴퓨터 바둑 시스템으로는 처음으로 핸디캡 [152]없는 프로 바둑꾼을 물리쳤다.초인적인 수준의 포커, Pluribus[q], Cepheus [154]등 불완전한 정보 게임을 다루는 프로그램도 있습니다.2010년대 딥마인드는 다양한 아타리 게임을 스스로 [155]배울 수 있는 '일반화된 인공지능'을 개발했다.
2020년까지 거대한 GPT-3(당시 가장 큰 인공 신경 네트워크)와 같은 자연 언어 처리 시스템은 벤치마크의 [156]내용을 상식적으로 이해하지는 못했지만 기존 벤치마크에서 인간의 성능을 일치시켰다.DeepMind의 AlphaFold 2(2020)는 단백질의 [157]3D 구조를 수개월이 아닌 몇 시간 안에 근사할 수 있는 능력을 입증했습니다.다른 응용 프로그램들은 사법 [158]결정의 결과를 예측하고, 예술(시 또는 그림 등)을 창조하고, 수학 이론을 증명한다.

WIPO는 2019년 특허 출원 건수와 특허 출원 건수에서 AI가 가장 많은 신흥 기술이라고 발표했으며, 시장 규모에서는 사물인터넷이 가장 큰 것으로 추정했다.그 뒤를 이어 빅데이터 기술, 로봇 공학, AI, 3D 프린팅, 5세대 모바일 서비스(5G)[159]가 뒤를 이었다.1950년대 AI가 등장한 이후 혁신가에 의해 3400만건의 AI 관련 특허출원이 이뤄졌고 연구진에 의해 160만건의 과학논문이 발표됐으며 2013년 이후 AI 관련 특허출원의 대다수가 발표됐다.AI 특허출원 상위 30개 중 26개 기업이 대표하고 나머지 [160]4개 기업이 대학이나 공공연구기관이다.발명품 대비 과학논문 비율이 2010년 8대 1에서 2016년 3대 1로 크게 감소해 이론연구에서 상업용 제품 및 서비스 분야 AI 기술 활용으로 전환했음을 시사하는 것으로 풀이된다.머신러닝은 특허에 공개된 지배적인 AI 기술로, 식별된 발명품 중 3분의 1 이상(2016년 출원된 총 167038건의 AI 특허에 대해 출원된 134777건의 머신러닝 특허)에 포함되어 있으며, 컴퓨터 비전이 가장 인기 있는 기능 애플리케이션이다.AI 관련 특허는 AI 기술과 응용 분야를 공개하는 것은 물론, 응용 분야나 산업을 지칭하는 경우도 많다.2016년에는 통신(15%), 교통(15%), 생명 및 의학(12%), 개인용 기기, 컴퓨팅 및 인간-컴퓨터 상호작용(11%) 순으로 20개의 응용 분야가 확인되었습니다.기타 부문에는 은행, 엔터테인먼트, 보안, 산업 및 제조업, 농업, 네트워크(소셜 네트워크, 스마트 시티 및 사물 인터넷 포함)가 포함되었습니다.IBM이 8,290개의 특허를 출원해 가장 많은 AI 특허 포트폴리오를 보유하고 있으며, 마이크로소프트가 5,930개의 특허를 [160]출원해 그 뒤를 잇고 있다.
법적 측면
인공지능의 응용 - 요다위키
인공지능의 응용 Applications of artificial intelligence 기계에 의해 표시되는 인텔리전스 응용 프로그램 인공지능(AI)은 산업계와 학계 전반에 걸쳐 특정 문제를 완화하기 위해 응용 프로그램에 사용되
yoda.wiki
인공지능 연대표 - 요다위키
인공지능 연대표 Timeline of artificial intelligence 인공지능 역사상 주목할 만한 사건 연표 이것은 인공지능의 연대표입니다. 어쩌면 합성 지능의 연대표이기도 합니다. 20세기 이전 날짜. 발전 고대
yoda.wiki
'토론방 -Q&A' 카테고리의 다른 글
| 컴퓨터 소개 (1) | 2023.03.13 |
|---|---|
| 인디안 밥 만들기 (0) | 2023.02.25 |
| 정보통신접근성(WA) 인증 (0) | 2023.02.14 |
| Lev Nikolayevich Tolstoy (0) | 2023.02.12 |
| 생식의학 -기초과학 (0) | 2023.02.03 |



